文章集中整理总结mysql分库分表开源产品,分布式数据库的设计,以及实际应用案例等相关内容,部分附上本文作者实际应用过程中的理解。
本文感谢sjdbc,mycat,姜承尧,林涛等文章提供的精彩介绍。
1、先抛出两个问题
问题一、当mysql单表数据量爆炸时,你怎么办?
问题二、当你的数据库无法承受高强度io时你怎么办?
2、 基本概念
2.1 谈数据库分片需要首先确定以下概念
1) 单库,就是一个库
2) 分片(sharding),分片解决扩展性问题,属于水平拆分,引入分片,就引入了数据路由和分区键的概念。分表解决的是数据量过大的问题,分库解决的是数据库性能瓶颈的问题。
3) 分组(group),分组解决可用性问题,分组通常通过主从复制(replication)的方式实现。(各种可用级别方案单独介绍)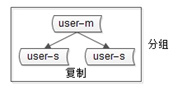
4) 互联网公司数据库实际软件架构是(大数据量下):又分片,又分组(如下图)
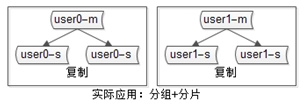
3、 分片
3.1 水平拆分,垂直拆分都是什么?
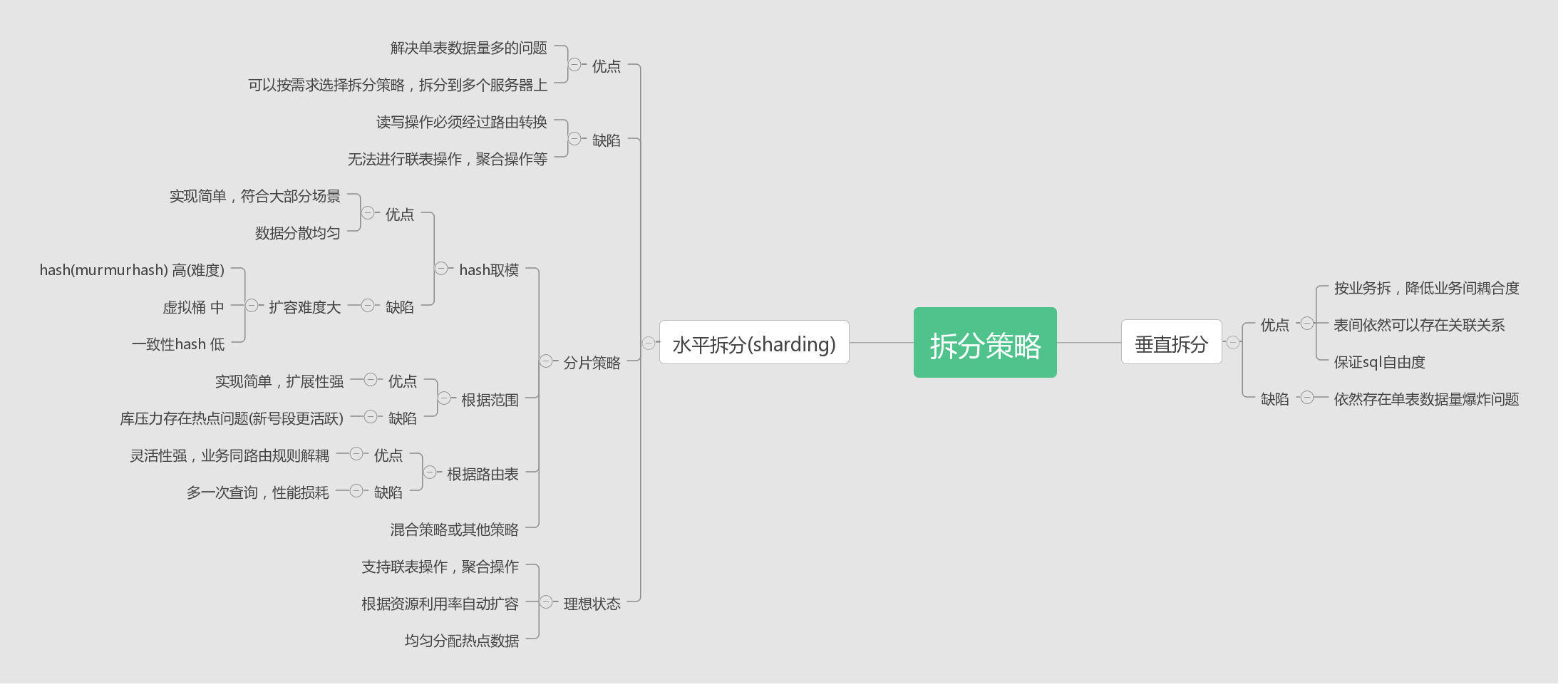
分区表?1)若不走分区键很容易出现全表锁,并发上来后简直是灾难。2)自己分库分表,自己掌控业务场景、访问模式,可控。mysql分区表官方介绍是针对myisam做的优化,你知道他怎么玩的?分半天还是一个ibdata是不是很尴尬
3.2 为什么分表?
关系型数据库在大于一定数据量的情况下检索性能会急剧下降。在面对互联网海量数据情况时,所有数据都存于一张表,显然会轻易超过数据库表可承受的数据量阀值。这个单表可承受的数据量阀值,需根据数据库和并发量的差异,通过实际测试获得。
水平拆分如果能预估规模,越早做成本越低。
2.3 为什么分库?
单纯的分表虽然可以解决数据量过大导致检索变慢的问题,但无法解决过多并发请求访问同一个库,导致数据库响应变慢的问题。所以通常水平拆分都至少要采用分库的方式,用于一并解决大数据量和高并发的问题。这也是部分开源的分片数据库中间件只支持分库的原因。
3.4 分布式事务?
但分表也有不可替代的适用场景。最常见的分表需求是事务问题。同在一个库则不需考虑分布式事务,善于使用同库不同表可有效避免分布式事务带来的麻烦。目前强一致性的分布式事务由于性能问题,导致使用起来并不一定比不分库分表快。目前采用最终一致性的柔性事务居多。分表的另一个存在的理由是,过多的数据库实例不利于运维管理。
mysql本身?
消息补偿?
2PC?
3.5 小结
综上所述,最佳实践是合理地配合使用分库+分表。
3.6 如何自己实现分库分表?
1) dao层,首先通过分区键算出库名表名(如shardKey%shardNum 算出来表index如y,然后y/(shardNum/sourceNum)=x,y是表下标,x是库下标)。
2) 把source从spring容器中拿出来,把表名当参数传进去,拼成分片后的sql。
3) 思路大概是(select … from order where … -> 先拿到db_x的source 然后 select … from order_y where …)
你想这么干?你已经成功了。当然淘宝和当当的架构师也是这么干的。
3.7 SO,不需要我们亲自动手,其实你需要做的只是按照实际需求挑选而已。
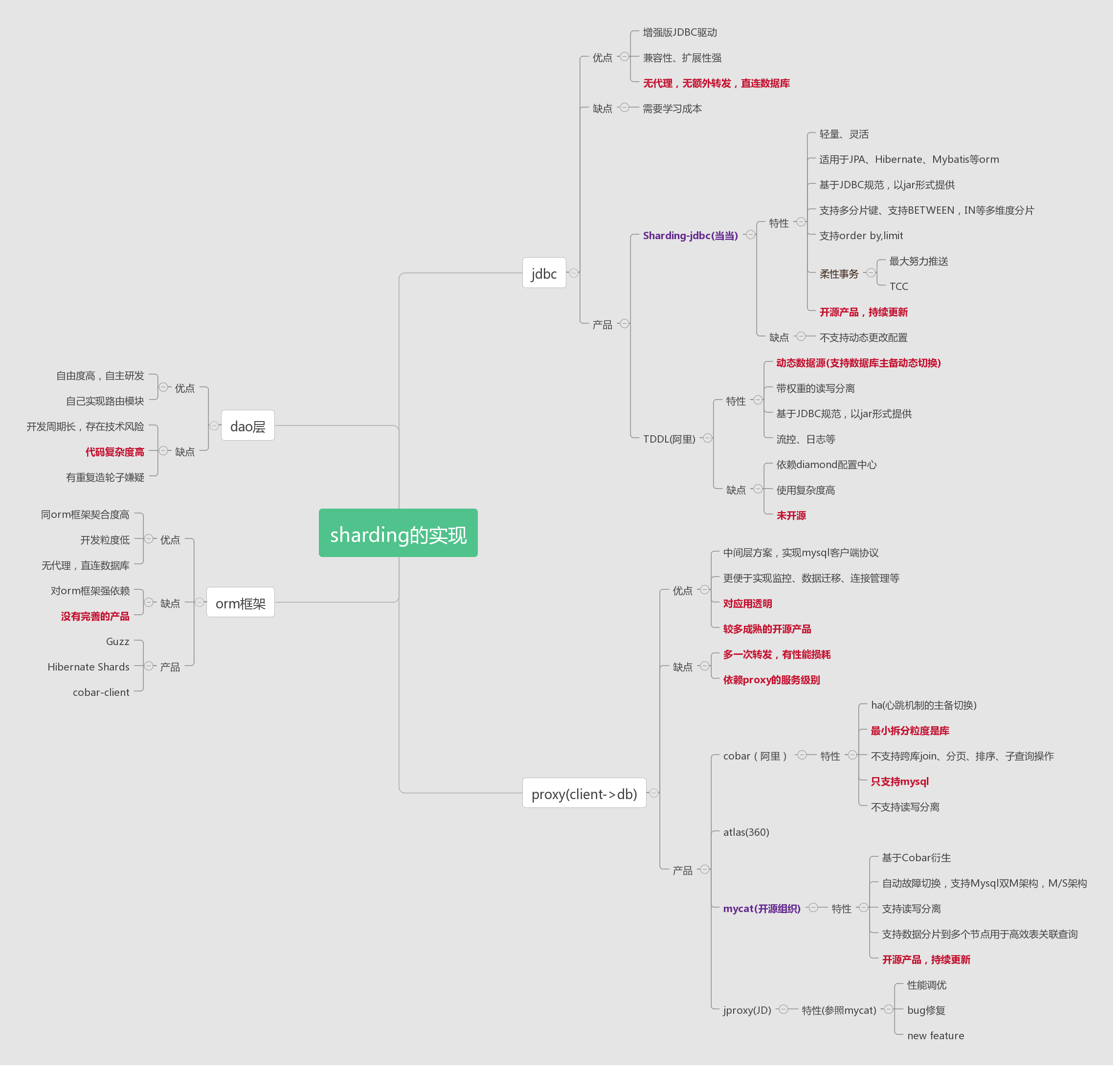
3.8 重点介绍两个产品,先不说具体配置,只说思想
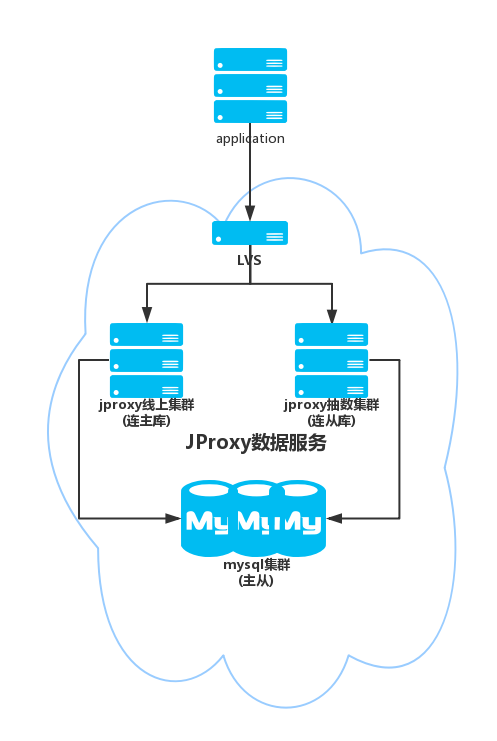
1) sharding-jdbc(所处位置,通用数据访问层,部署在客户端的jar包,用于将用户的SQL路由到指定的数据库中)
盗一波图
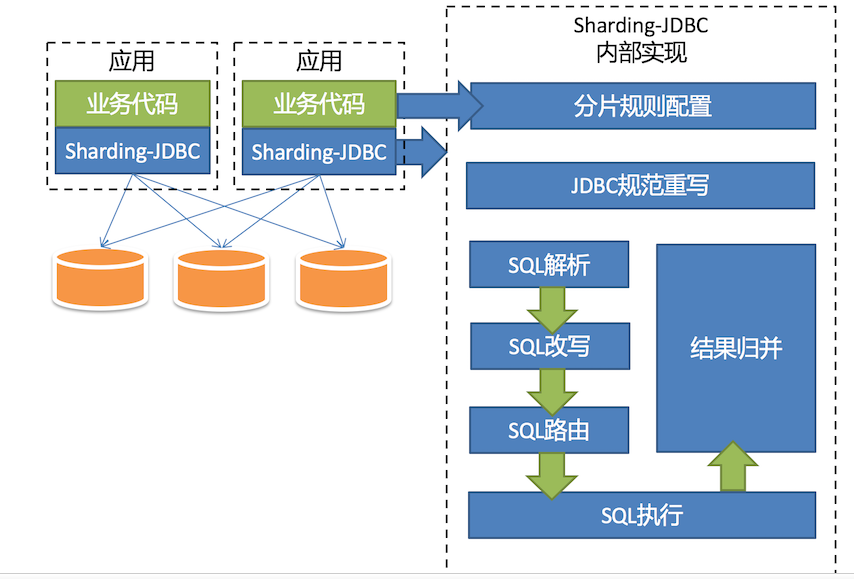

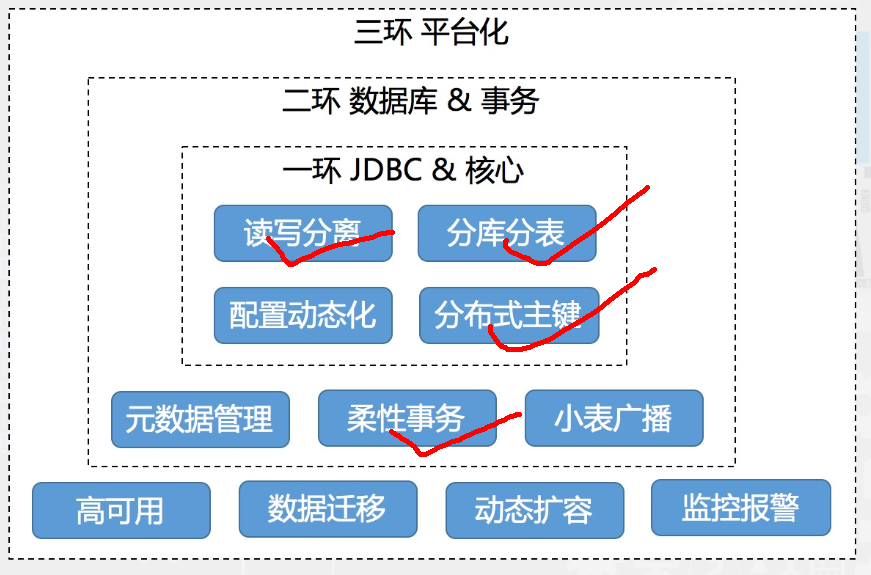
2) jproxy
jproxy是什么?
jproxy提供MariaDB, MySQL等数据库的统一接入访问,拥有流量过载保护,数据自动拆分,可配置路由规则,数据无缝迁移等功能。
应用场景:数据需要分库分表,自动扩容的应用。
为什么分片都是2的n次方?a % (2^n) 等价于 a & (2^n - 1) 其中一个原因就是位运算
扩容? 虚拟桶。 极限就是一片一库。
演变过程 cobar->mycat->jproxy
mycat是什么?
简单的说,就是:一个彻底开源的,面向企业应用开发的“大数据库集群”。支持事务、ACID、可以替代Mysql的加强版数据库,一个的数据库中间件产品。
- 其优势具有:
1) 基于阿里开源的Cobar产品而研发,Cobar的稳定性、可靠性、优秀的架构和性能
2) 拥有众多成熟的使用案例
3) 强大的团队(其参与者都是5年以上资深软件工程师、架构师、DBA等)
4) 开源,创新,持续更新
盗一波图
4、 分组
4.1 为什么分组?
分组解决可用性问题
mysql的ha 网洛上的都是vip漂移实现的
盗一波图
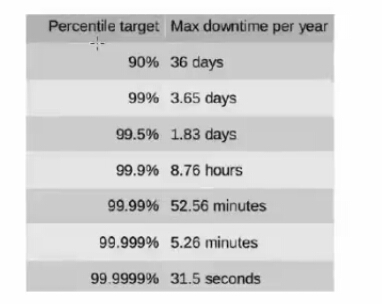
方案一:MYSQL主从复制(单活)
方案二:双主(单活),failover比单主简单
方案三:双主配SAN存储(单活)
方案四:DRBD 双主配DRBD (单活)
方案五:NDB CLUSTER
共享存储? 不需要复制了 更高的一致性
真正的高并发场景,什么架构都抗不住,老老实实用缓存。
需要大量读的场景尽量做到最终一致性。
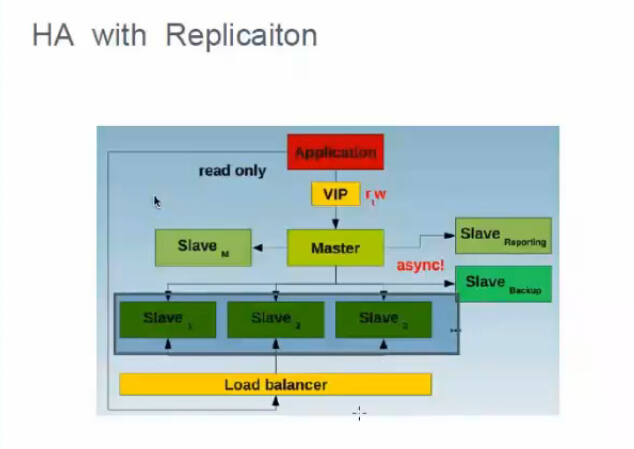

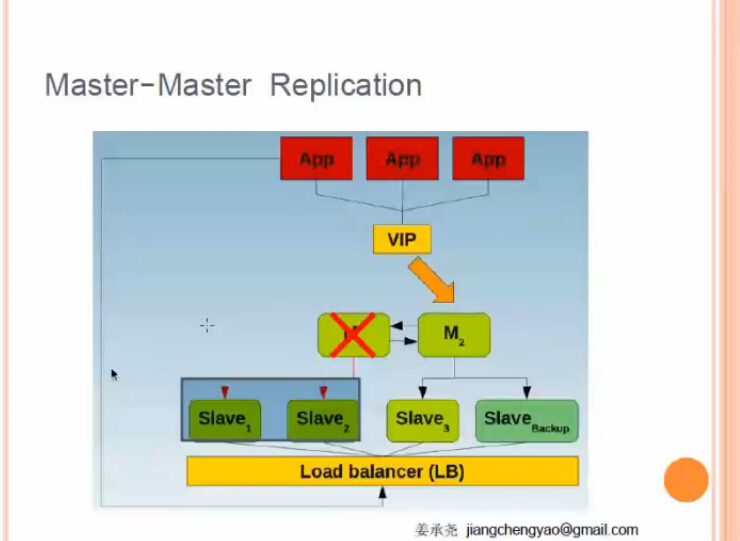


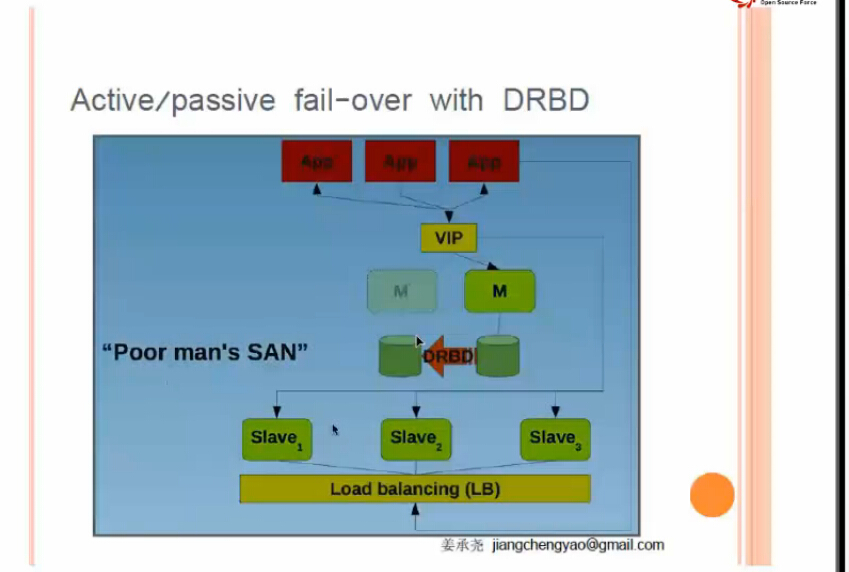

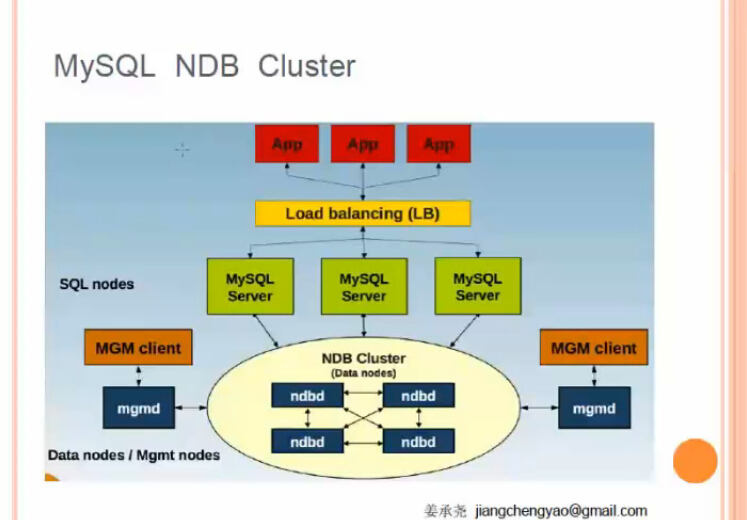
4.2 同步,异步,半同步
1) 异步复制 (mysql默认)
Master将事件写入binlog,但并不知道Slave是否或何时已经接收且已处理。当Slave准备好才会向Master请求binlog。缺点:不能保证一些事件都能够被所有的Slave所接收。
2) 同步复制
Master提交事务,直到事务在
所有的Slave都已提交,此时才会返回客户端,事务执行完毕。缺点:完成一个事务可能会有很大的延迟。
3) 半同步复制
半同步复制工作的机制处于同步和异步之间,Master的事务提交阻塞,
只要一个Slave已收到该事务的事件且已记录。它不会等待所有的Slave都告知已收到,且它只是接收,并不用等其完全执行且提交。
半同步复制的步骤:
i.当Slave主机连接到Master时,能够查看其是否处于半同步复制的机制。
ii.当Master上开启半同步复制的功能时,至少应该有一个Slave开启其功能。此时,一个线程在Master上提交事务将受到阻塞,直到得知一个已开启半同步复制功能的Slave已收到此事务的所有事件,或等待超时。
iii.当一个事务的事件都已写入其relay-log中且已刷新到磁盘上,Slave才会告知已收到。
iv.如果等待超时,也就是Master没被告知已收到,此时Master会自动转换为异步复制的机制。当至少一个半同步的Slave赶上了,Master与其Slave自动转换为半同步复制的机制。
v.半同步复制的功能要在Master,Slave都开启,半同步复制才会起作用;否则,只开启一边,它依然为异步复制。
4.3 ha方案
4.3.1 MHA
4.3.2 MMM
5、 应用案例
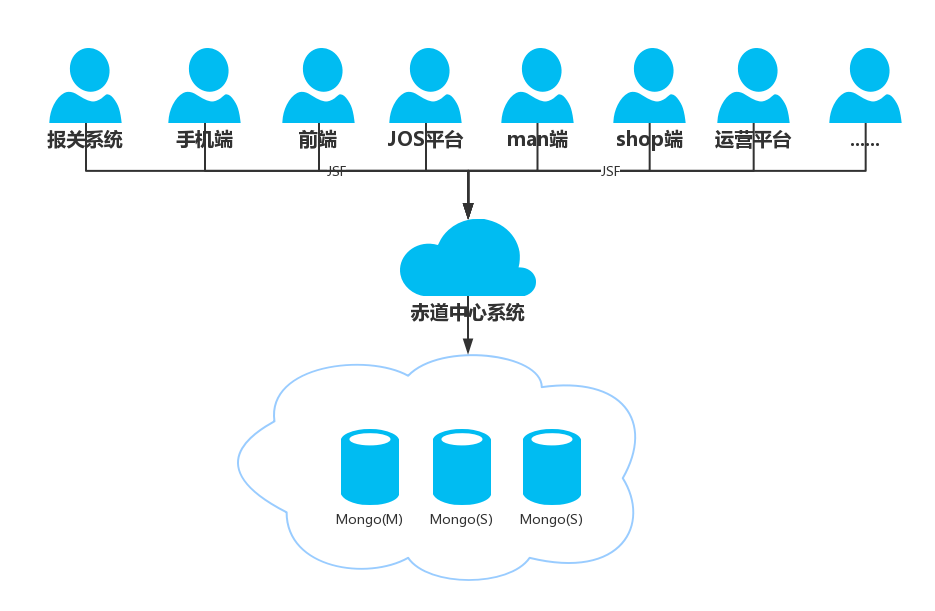
5.1 记录一次mongo迁移mysql的过程(分库分表使用jproxy)
mongo怎么了?跟分片无关的部分简单说。
mongo很好,只是业界并没有成熟的MongoDB运维经验,jd too。
像高并发的系统 订单和库存 商品 还是拿nosql把,高并发的写,也不会打挂他,比如hbase,顶多GC频繁点,但是也是可用的。
一致性完全可以CAS搞定,而不是mysql的排他锁。
- 迁移数据库的一个方案
1) 中心化(统一入口)
2) 双写(先同步写mysql如果发生异常改异步,尽量避免服务不可用)
3) 倒库(jproxy支持通过游标形式全量遍历库-逐个表操作,可以利用其异步同步数据)
4) 数据校验
5) 切库提供服务
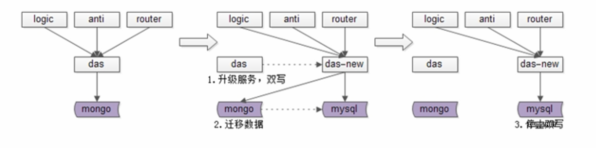
去mongo+优化方案(此处引入了分片的概念)
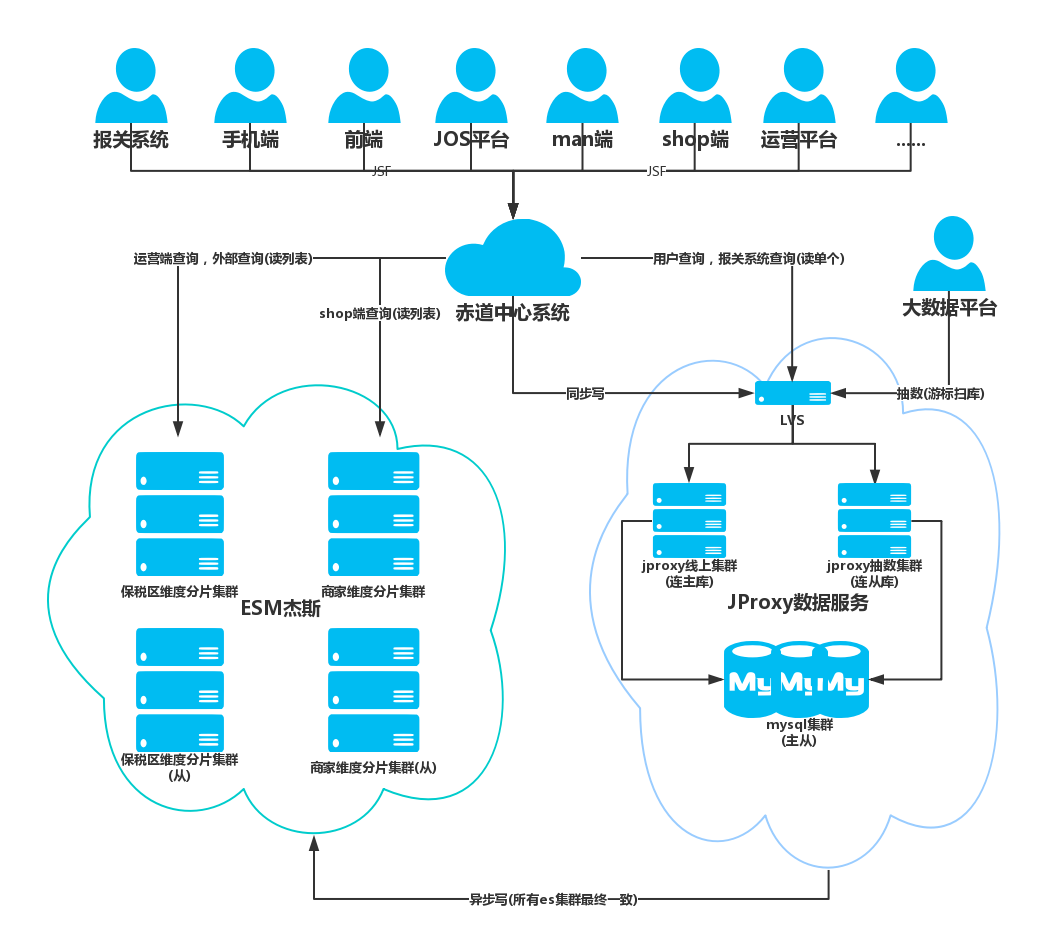
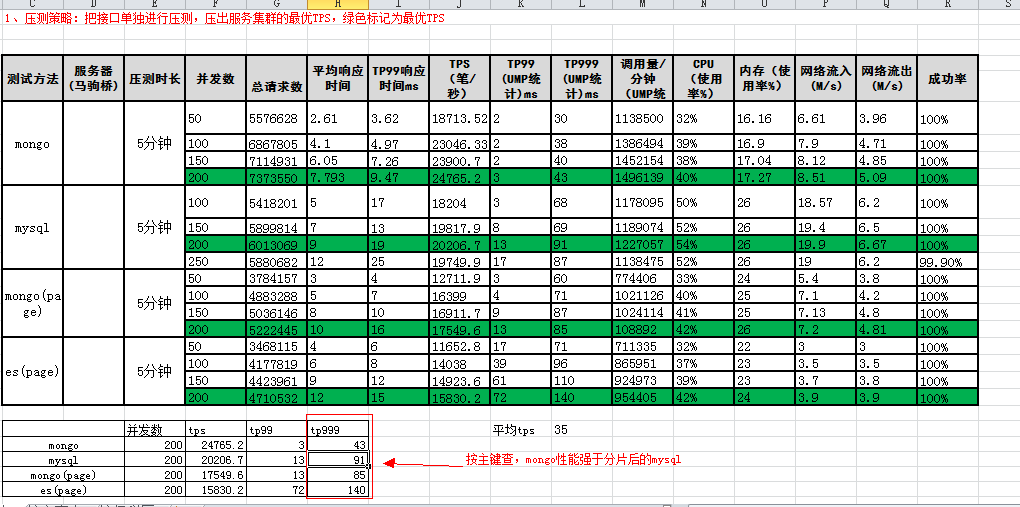
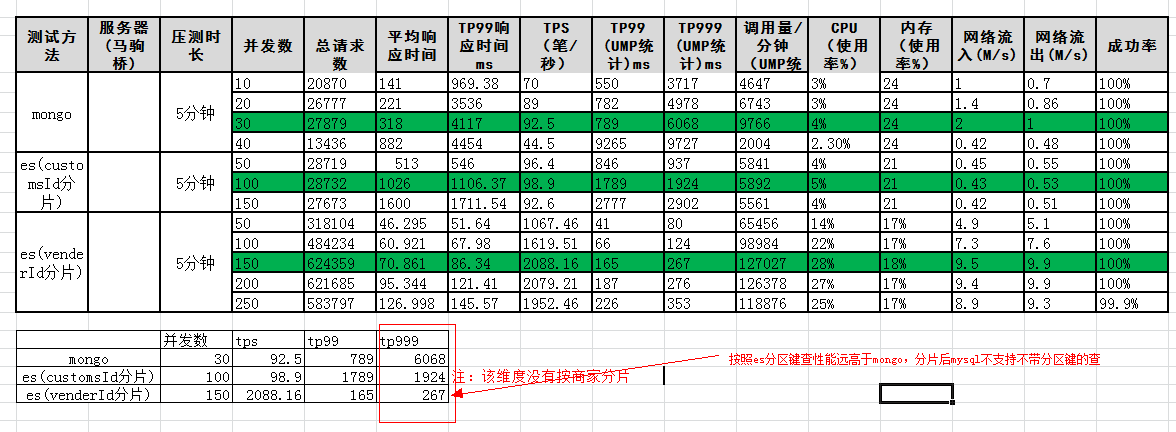
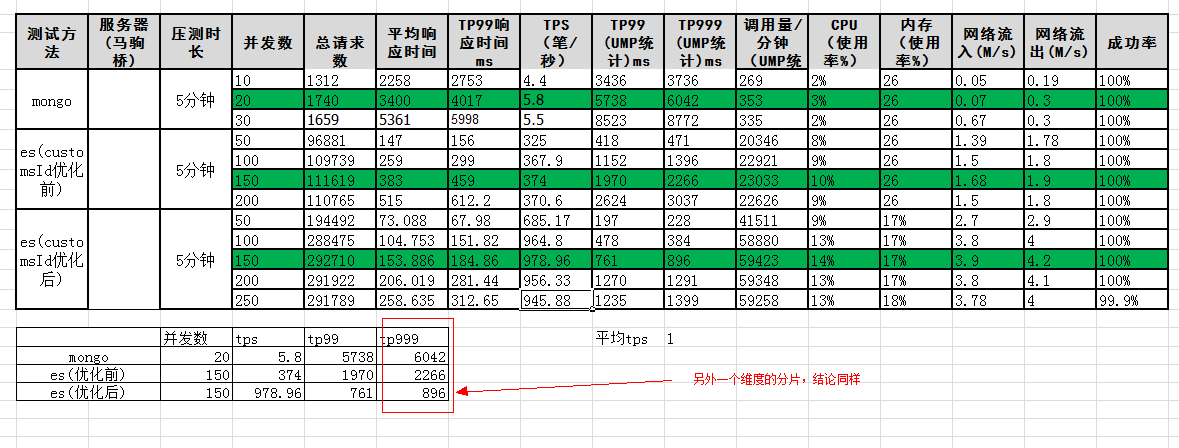
压测与性能
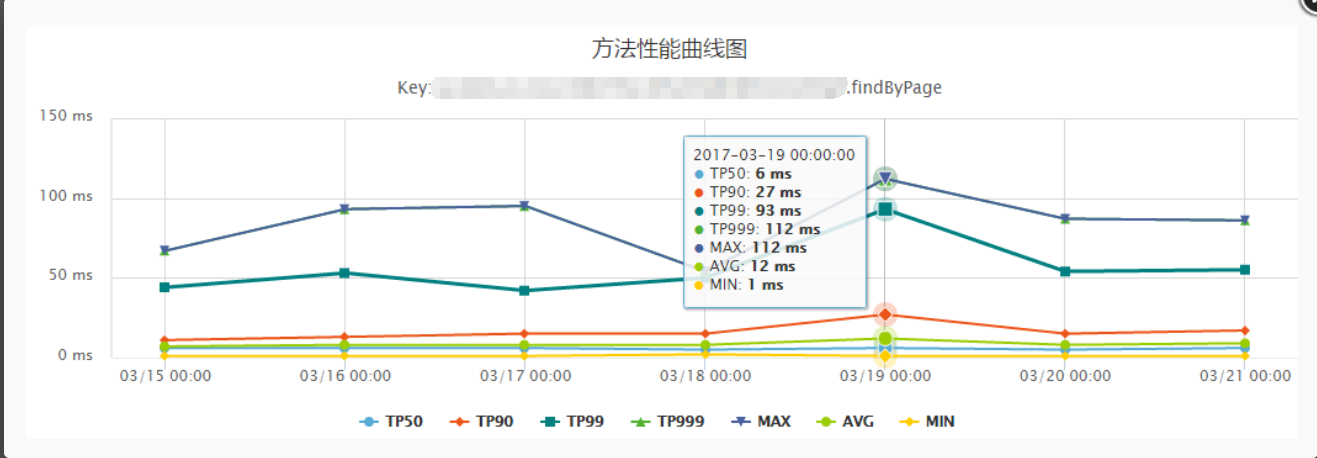
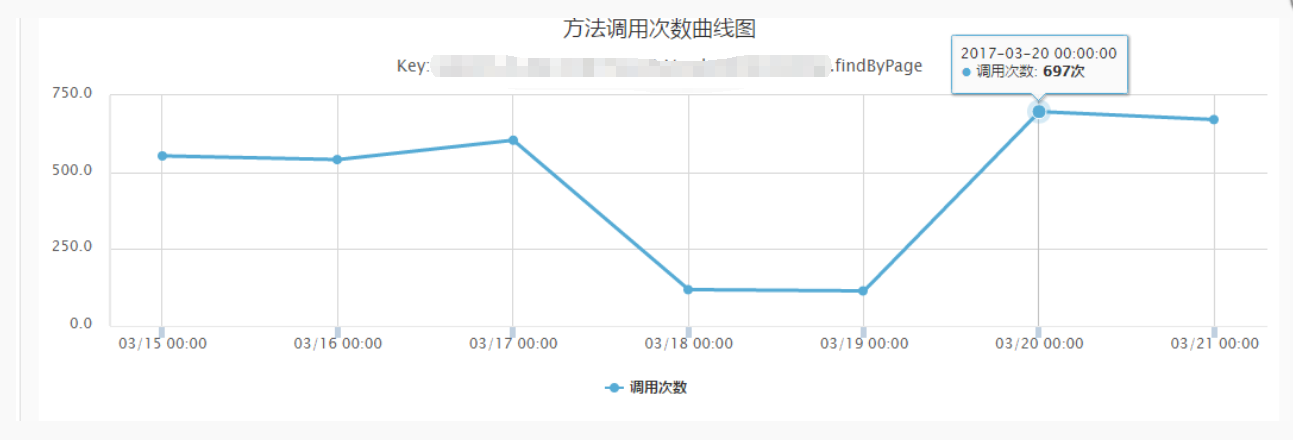
去mongo任务线
| 类型 | 任务 | 备注 | 影线系统 | 风险 |
|---|---|---|---|---|
| design | 海关迁移方案设计评审 | … | … | 无 |
| design | 分库分表技术选型 | jproxy | … | 无 |
| apply | 申请迁移相关应用(辅助系统) | 跑批任务 | … | 无 |
| apply | 申请mysql集群 | dbs系统 | … | 无 |
| apply | 申请jproxy集群 | 直接找接口人 | … | 无 |
| apply | 申请es集群 | esm杰斯 | … | 无 |
| coding | trace表服务中心化 | soa | center | 高 |
| coding | 涉及trace业务逻辑梳理,全部切换中心接口 | 接口完全适配 | platform | 低 |
| verify | 回归测试,并线上走单验证一段时间 | 先预发后正式 | … | 高 |
| coding | 实现mysql版本共2个表sql映射文件 | 基于自主研发的generator | center | 低 |
| verify | mysql版本sql映射文件单元测试 | 基于自主研发的generator | center | 低 |
| coding | trace表实现基于jproxy的分库分表 | 128个库(主) 1主3从 | center | 中 |
| coding | es分别按照商家id分片,保税区id分片,异步写,读开放jsf | 2套集群4套索引 | es | 中 |
| coding | 中心接口加入代理层,可利用开关切换读mongo/mysql/es | … | center | 高 |
| coding | 异步补偿mongo,mysql,es功能开发 | 基于jmq | platform | 中 |
| coding | 代理层实现mongo和mysql版本互为主被双写(mongo主),异步写es | 双11后mysql主 | center | 高 |
| verify | 线上开双写(包括es) | 两套es集群 | … | 中 |
| coding | 倒库功能开发,数据校验功能开发 | reactor | config | 高 |
| verify | 倒库,并进行数据校验 | 校验规则(特殊字段不校验) | … | 高 |
| verify | 对中心接口进行压测 | 线上,压测环境隔离(jsf别名) | … | 高 |
| coding | 优化配置(mysql调整最大连接数,es使用filterCache) | … | … | 高 |
| verify | 对中心接口进行压测 | … | … | 高 |
| verify | 升级后架构正式上线 | … | … | 无 |
| verify | 监控切换mysql之后的接口性能 | … | … | 无 |
| verify | 监控切换mysql之后对相关依赖系统的影响 | … | … | 无 |
| todo | 停mongo写 | … | … | 无 |
| todo | 继续迁移海关mongo中其他表(以上均为trace表) | … | … | 无 |
| todo | 彻底下线mongo数据库服务器,只保留mysql服务器 | … | … | 无 |
5.2 记录一次异构具有复杂分片规则数据库的过程
5.2.1 难点
交易库存复杂的分片规则,数据量大,更新频繁,一致性保证。
回到本源,缓存+队列
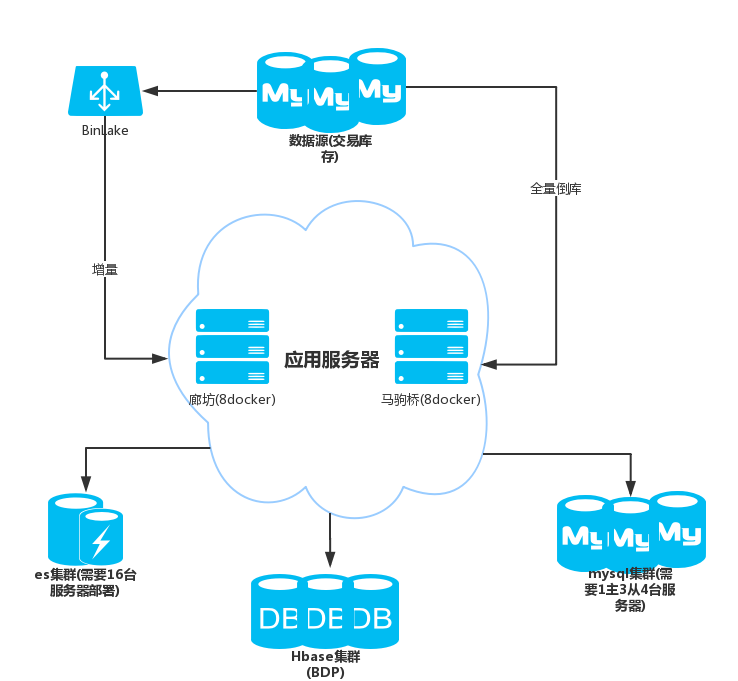
5.2.2 不跑题,我们就说分片部分,如何接手一个复杂分片规则的数据库?
参考案例如何异构一个数十亿级别的数据库
有多复杂? 6000+表,28个库,4套分片规则。(解决方案 sharding-jdbc)